ETL
This time I downloaded all the historial exchange rates from 1999 to the current date of 25-Mar-2025.
Following on from my previous blog loading historical RBA Exchange Rate data. The CSV file now has 134,462 rows including the header. For this amount of data we're better off to use a more formal structured ETL approach.
Modify The Python Script
The first thing I had to do was modify my Python script a little as the initial row that I use to validate the file as an RBA historical exchange rate file changed. Additionally I implemented another option, append_to_output, which if "y" appends data to the file rather than overwriting it.
Also on eyeballing the data I notice the word "Closed" on some dates which must be public holidays for that foreign country. I'll need to account for this is my process.
- import os
- import sys
- CLI_SEPARATOR = "======================================================================\n"
- CLI_HEADER = "\nprocess_forex_csv\nProcesses CSV version of RBA Exchange Rate history:\nhttps://www.rba.gov.au/statistics/historical-data.html#exchange-rates\nfrom supplied format to a format ready for ETL"
- CLI_USAGE = "Usage:\nprocess_forex_csv.py [input_filename] [output_filename] [format_as_sql (y/n)] [append_to_output]\n"
- OUTPUT_HEADER = "Date,Currency,Rate\n"
- FILE_HEADER_1 = "EXCHANGE RATES ,,,,,,,,,,,,,,,,,,,,,,,"
- FILE_HEADER_2 = "HISTORICAL DAILY EXCHANGE RATES OF THE AUSTRALIAN DOLLAR AGAINST:"
- FOREX_HEADER = "Series ID"
- months = {
- "jan": "01",
- "feb": "02",
- "mar": "03",
- "apr": "04",
- "may": "05",
- "jun": "06",
- "jul": "07",
- "aug": "08",
- "sep": "09",
- "oct": "10",
- "nov": "11",
- "dec": "12"
- }
- class ProcessForexCSV:
- def __init__(self, input_filename, output_filename, format_for_sql, append_to_output):
- self.input_filename = input_filename
- self.output_filename = output_filename
- self.format_for_sql = format_for_sql
- self.append_to_output = append_to_output
- self.currencies = []
- def process_file(self):
- input_file_path = os.path.join(os.getcwd(), self.input_filename)
- output_file_path = os.path.join(os.getcwd(), self.output_filename)
- with open(input_file_path, "rt") as f:
- new_lines = ""
- line = f.readline()
- if line.find(FILE_HEADER_1) < 0 and line.find(FILE_HEADER_2) < 0:
- print("Invalid file format.")
- return
- line = f.readline()
- while line.find(FOREX_HEADER) < 0:
- line = f.readline()
- tokens = line.split(",")
- i = 0
- for token in tokens:
- if i > 0:
- self.currencies.append(token[len(token)-3:].strip())
- i += 1
- print("Currencies:\n{0}".format(CLI_SEPARATOR))
- for currency in self.currencies:
- print("{0}".format(currency))
- line = f.readline().strip()
- line_count = 0
- while line != "":
- line_count += 1
- line_tokens = line.split(",")
- token_count = len(line_tokens)
- exchg_date = line_tokens[0]
- original_exchg_date = exchg_date
- date_tokens = exchg_date.split("-")
- exchg_date = date_tokens[2] + months[date_tokens[1].lower()] + date_tokens[0]
- i = 1
- while i < token_count:
- if line_tokens[i] == "":
- line_tokens[i] = "NULL"
- exchg_line = ""
- if not self.format_for_sql:
- exchg_line = "{0},{1},{2}\n".format(original_exchg_date, self.currencies[i-1], line_tokens[i])
- else:
- exchg_line = "select '" + exchg_date + "','" + self.currencies[i-1] + "'," + line_tokens[i] + " union all\n"
- i += 1
- if exchg_line != "":
- #print(exchg_line)
- new_lines += exchg_line
- line = f.readline().strip()
- f.close()
- # get rid of the final "union all"
- if self.format_for_sql:
- new_lines = new_lines[:len(new_lines)-len(" union all\n")]
- else:
- new_lines = new_lines[:len(new_lines)-len("\n")]
- #print(new_lines)
- file_mode = "at" if self.append_to_output else "wt"
- with open(output_file_path, file_mode) as f2:
- if not self.format_for_sql and not self.append_to_output:
- f2.write(OUTPUT_HEADER)
- f2.write(new_lines)
- f2.close()
- print("{0}\n{1} exchange rates {2} to {3}\n{4}".format(CLI_SEPARATOR, line_count, "appended" if self.append_to_output else "written", self.output_filename, CLI_SEPARATOR))
- if __name__ == "__main__":
- print(CLI_HEADER)
- print(CLI_SEPARATOR)
- print(CLI_USAGE)
-
- if len(sys.argv) == 5:
- input_filename = sys.argv[1]
- output_filename = sys.argv[2]
- format_for_sql = True if str(sys.argv[3]).lower() == "y" else False
- append_to_output = True if str(sys.argv[4]).lower() == "y" else False
- process = ProcessForexCSV(input_filename, output_filename, format_for_sql, append_to_output)
- process.process_file()
- else:
- print("Invalid number of parameters.")
Database Staging
I will use ETL to populate a staging table in the database. The data type of the columns in simply varchar.
- create table stage_forex
- (
- stage_id int not null identity,
- exchg_date varchar(11) not null,
- exchg_currency varchar(5) not null,
- exchg_rate varchar(20) null,
- constraint PK_stage_forex primary key (stage_id)
- )
Now a stored procedure to migrate the data from staging into the final tables. I have explicitly declared a transaction here for purposes of exposition but in reality the insert statement is a single transaction anyway.
Note line 8 which converts "null", "closed" or "N/A" to NULL. Also the exchange rate is converted to the data type of the destination column, decimal (19,4). This is an ideal data type for use with currency values.
- create proc sp_migrate_forex as
- begin
- begin transaction
- begin try
- insert forex (exchg_date, exchg_currency, exchg_rate)
- select convert(date, exchg_date), convert(varchar(3), exchg_currency),
- case when exchg_rate = 'null' or lower(exchg_rate) = 'closed' or lower(exchg_rate) = 'n/a' then NULL
- else convert(decimal(19,4), exchg_rate) end
- from stage_forex
- commit transaction
- end try
- begin catch
- rollback transaction
- raiserror ('Error during forex migration', 10, 1)
- end catch
- end
The ETL Package
I am using SQL Server Integration Services and Visual Studio 2022 to build the ETL package.
- I create a new Integration Services project
- I drag a Data Flow Task on to the canvas and right-click Edit
- I drag a Source Assistant object onto the canvas and select New Connection
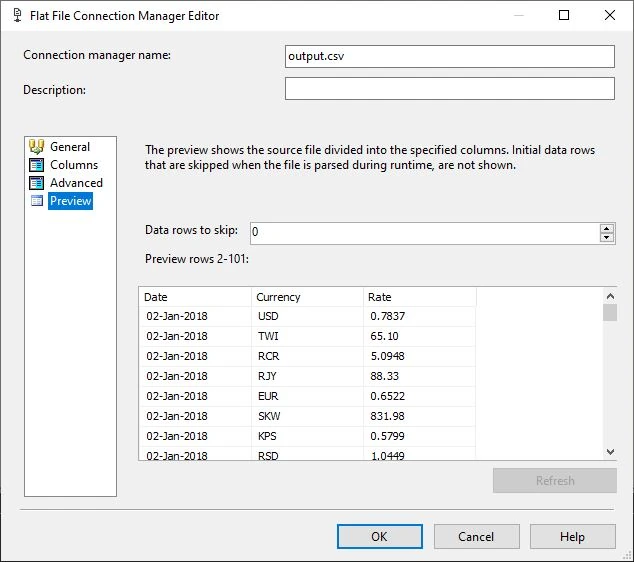
- I configure the connection to my output.csv created by the Python scripts:

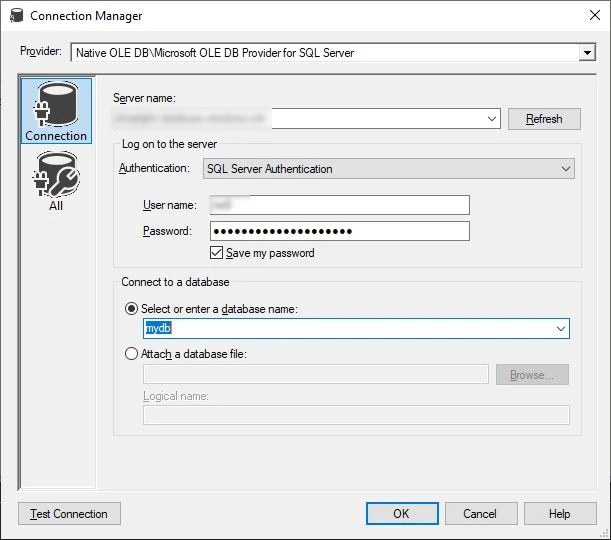
I drag a Destination Assistant object onto the canvas, select SQL Server as the Destination type then double click New. I choose the Microsoft OLE DB Provider For SQL Server from the Provider list then enter my credentials:
I connect the Flat File Source to the OLE DB Destination:
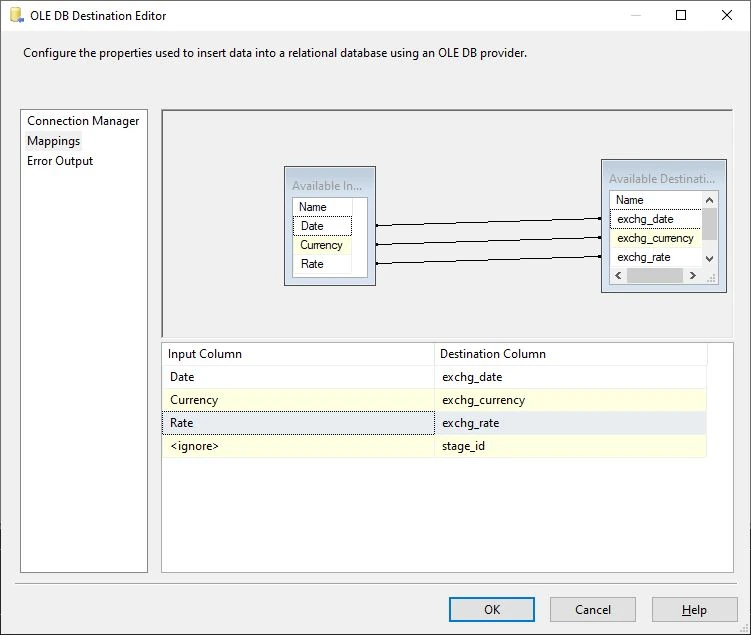
I right-click Edit the OLE DB Destination, select stage_forex as the destination table then configure the mappings:
I execute the SSIS package and after a very brief delay it reports successful execution.
I run a query in SSMS to determine if there are any potentially problematic exchange rate values and identify the value N/A which I had not accounted for in my migration stored procedure so I modify it accordingly.
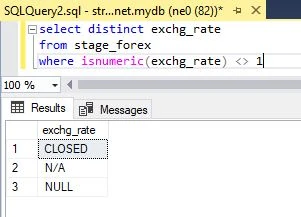
Finally I execute exec sp_migrate_forex in SSMS and after a brief delay the migration is complete. It reports 134,461 rows affected which is exactly the original number of rows in my CSV file minus the heading row.
I have constructed a Forex Chart page to query the exchange rates from Azure.
Ed. I moved the data to a MySQL database closer to the code to reduce latency.